Overview
GPU管理とは何ですか?
GPU管理機能は、オペレーター指向の機能であるGPUダッシュボードを通じてすべてのGPUコンポーネントの状態を管理し、物理的/論理的な容量、プールリクエスト、およびGPUリソースの割り当てを通じてGPUの使用状況を管理します。
GPUプールの作成から最適化、監視までのライフサイクル全体を、単一のインターフェースを通じて管理できます。
主な機能
- GPU Capacity: 実際の物理GPUハードウェアの容量をプールとして管理することで、利用率を向上させます。
- NodeCapacity: 各GPUノードの全体的な容量に関する情報
- GpuCapacity: 個々のGPUデバイスの詳細
- Profile: 実際に割り当てられたポッド情報のマッピングの目的(ワークロード追跡)
- SpecAndCount: プロビジョニングされたMIGまたはGPUリソースを管理するために使用されます
- GPU Pool Management: ワークロードタイプによってGPUをグループ化または分離し、プロジェクトレベルでプールとして管理します。
- GPU Monitoring: 電力消費、SMアクティビティ、およびメモリエラーによってGPUの使用状況を測定します。
アーキテクチャ参照
GPUは、Nvidia H100およびH200構成でNvidiaが提供するGPU管理スタックを通じて管理され、GPUのライフサイクル(コンテナスケジューリング、リソースの負荷ごとの管理、隔離など)はKubernetesに基づいて統合的に管理されます。 したがって、割り当てられたGPUは、Kubernetes上でのワークロードの振る舞いの原則(アプリ配布を通じたリソース割り当てなど)を適用します。
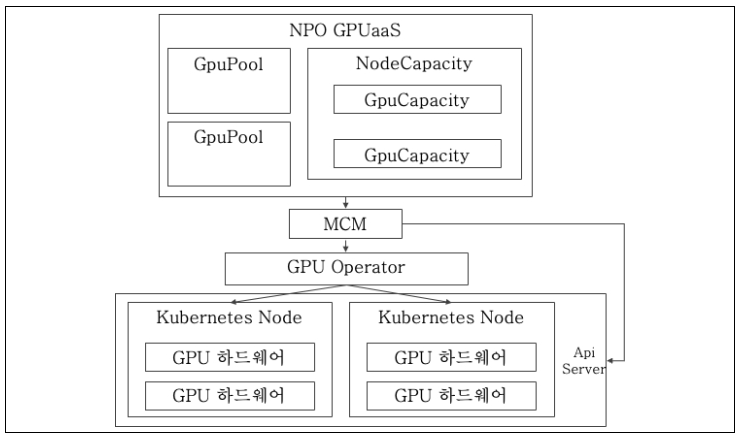
| Layer | Element | Role | Feature |
|---|---|---|---|
| Physics | Kubernetes Node | Physical Servers | サーバーリソースをホストする物理インフラストラクチャ |
| GPU Hardware | Physical GPU | AI関連の計算を担当 | |
| ロジック | Kubernetes Api Server | API サーバー | Kubernetes の制御 |
| オペレーター | GPU 管理 | GPU リソースの管理とプロビジョニング | |
| MCM (マルチクラスタ管理) | クラスター管理 | Kubernetes クラスター管理と GPU リソース | |
| キャパシティ | キャパシティ管理 | GPU プールと物理的なリソース間のリソース管理オブジェクト | |
| GPU プール | 使用状況の管理 | エンドユーザー に論理リソースとして割り当てられる管理オブジェクト |
GPU 管理方法
GPU は、Nvidia が A100 以降に導入したハードウェアベースの GPU 仮想化技術である GPUaaS 上の物理 GPU と独立した GPU インスタンスに分割された MIG の形で GPU リソースを管理します。
MIG (マルチインスタンス GPU) プロビジョニング
マルチインスタンス GPU (MIG) は、NVIDIA の革新的な技術で、単一の GPU を最大 7 つの独立した GPU インスタンスに分割することを可能にします。各インスタンスは専用のメモリ、キャッシュ、およびストリーミングマルチプロセッサを持ち、ハードウェアレベルで完全に隔離されて動作します。これにより、1 つのインスタンスの障害が他のインスタンスに影響を与えない安全なマルチテナント環境が提供されます。
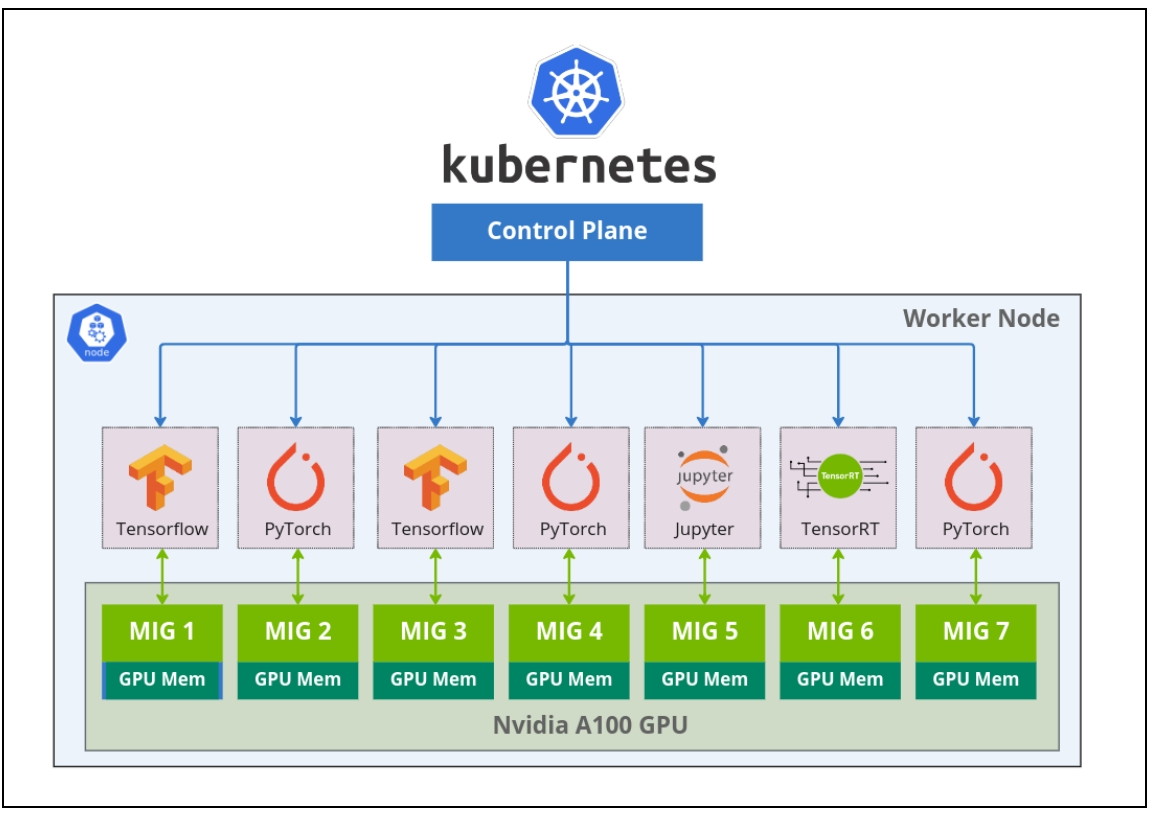
- リソース効率の最大化
- 複数のユーザーが同時に高価な GPU (例: A100) を利用
- フル GPU パフォーマンスを必要としないワークロードのコスト効率の良い使用
- アイドル GPU リソースを最小限に抑えることで ROI を改善
- マルチテナンシーのサポート
- 複数のプロジェクトやチーム間で同じ GPU を安全に共有
- 各インスタンス間の完全な隔離を確保 (メモリ、計算リソース)
- 1 つのインスタンスの障害が他のインスタンスに影響を与えない
- ワークロードのカスタム割り当て
- 推論タスク: 少量のメモリでも十分なパフォーマンスを提供
- 開発/テスト: 小さなリソースで迅速な反復開発を可能にします
- バッチ処理: 複数の小さなジョブを同時に並行して実行します
- 運用効率の向上
- GPUキューのレイテンシの削減(より多くのインスタンスが利用可能)
- スケジューリングとスケジューリングリソースの柔軟性の向上
- 使用に基づいた正確なコスト配分
- スケーラビリティと管理の容易さ
- 物理的なGPUを追加することなく、より多くのユーザーに対応
- 中央集権的なGPUリソース管理
- 動的リソース再配分による最適化
フルGPUプロビジョニング
MIGはすべてのワークロードに適しているわけではなく、高性能で大規模な並列処理を必要とする環境では、フルGPUを活用することが最も効果的です。 フルGPUの使用は主に大規模トレーニング(深層学習)、LLMトレーニング(GPT-3など)、大規模モデルの推論、高性能シミュレーション、科学計算に使用され、主にマルチGPU、ファインチューニングなどに使用されます。 これは、1つのワークロードでGPU全体を独占的に使用することを意味します。大規模なAIモデルや高性能コンピューティングタスクのトレーニングに最適化されています。

| Category | MIG (Multi-Instance GPU) | Full GPU |
|---|---|---|
| リソース構造 | GPUのハードウェアレベルのパーティショニング(1から7インスタンス) | GPU全体を単一のリソースとして使用 |
| 隔離レベル | ハードウェアレベルの隔離(メモリとキャッシュの隔離 ) | 共有リソース(単一のGPUに基づくリソース) |
| パフォーマンス | 高密度のマルチテナンシー | 最大パフォーマンス、高帯域幅利用率 |
| 適したワークロード | 推論、小規模ファインチューニング | 大規模トレーニング、マルチGPUトレーニング |
Billing Method: GPUaaSは、GPUプールの使用状況を自動的に追跡し、請求データを生成する請求サービスを提供します。GPUの使用は、プロジェクトレベルでのプール使用リクエストの承認後に請求可能となり、プールに割り当てられたリソースはそのプロジェクトに専用され、他のプロジェクトと共有することはできません。